What is actually happening to your document when you transform it into an OCR? Where are we taking it and why?
The process of Optical Character Recognition (OCR) is a small part of your IDM -Capture solution in INFOR OS.
Let me take you on your files journey from a regular document to an OCR one.
In the IDM-Capture frame of your INFOR operating system you have the option to simply “add a document” in the top right corner of the user interface. (also: https://cloudintegration.eu/recognition)
Your PDF document can be uploaded here to start the transformation journey that follows. The “add document” button brings you to a second window. Here you want to specify your document as a “supplier invoice OCR”.
You are now able to upload your document via drag and drop or you just choose from your own documents.
The hardest part for the customer is actually done after hitting the “save” button. You now find yourself in a spot, where all you have to do is wait for the OCR Server to do it’s magic:
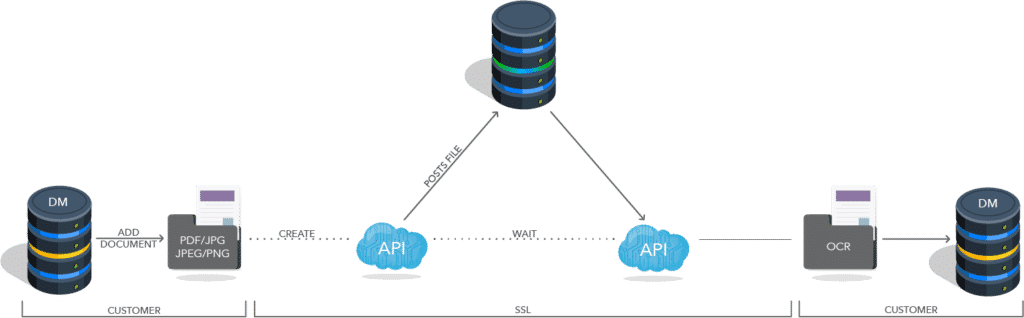
What is happening behind the curtain?
The document transforms into a xml file. An API (application programming interface) picks up the document and takes it to the original OCR server. This phase defines as the actual conversion of the document. That being the case, our fresh OCR file makes its way back towards your INFOR OS.
On this way, the file needs to run through one more “shape-swap” to integrate perfectly in your management system. Since we cannot integrate a pdf file just like this, it has to take shape as a Base64 document, as which it then uploads back onto your IDM.
The curtain opens back up again!
Back in your IDM you find a perfectly readable and accessible OCR document, that makes the whole management system perfectly organizable and uniform. You are now able to download it as a PDF again.
Enjoy happy customers and content coworkers!




