Why to learn it?
Spark has been reported to be one of the most valuable tech skills to learn.
Spark is quickly becoming one of the most powerful Big Data tools! You also have the ability to run programs up to 100x faster than MapReduce in memory.
What is Spark?
Apache Spark is an open-source distributed cluster-computing framework. Spark is a data processing engine developed to provide faster and easy-to-use analytics than Hadoop MapReduce. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs.
It was first released in February 2013 and has exploded in popularity due to it’s ease of use and speed. Before Apache Software Foundation took possession of Spark, it was under the control of University of California, Berkeley’s AMP Lab.
Spark can use data stored in a variety of formats:
- Cassandra
- AWS S3
- HDFS
- And more
Spark vs MapReduce
- MapReduce requires files to be stored in HDFS, Spark does not!
- Spark also can perform operations up to 100x faster than MapReduce
- Spark keeps most of the data in memory and MapReduce writes most of the data to disk
Spark RDDs
At the core of Spark is the idea of a Resilient Distributed Dataset (RDD)
Resilient Distributed Dataset has 3 main features:
- Distributed Collection of Data
- Parallel operation – partioned
- Ability to use many data sources
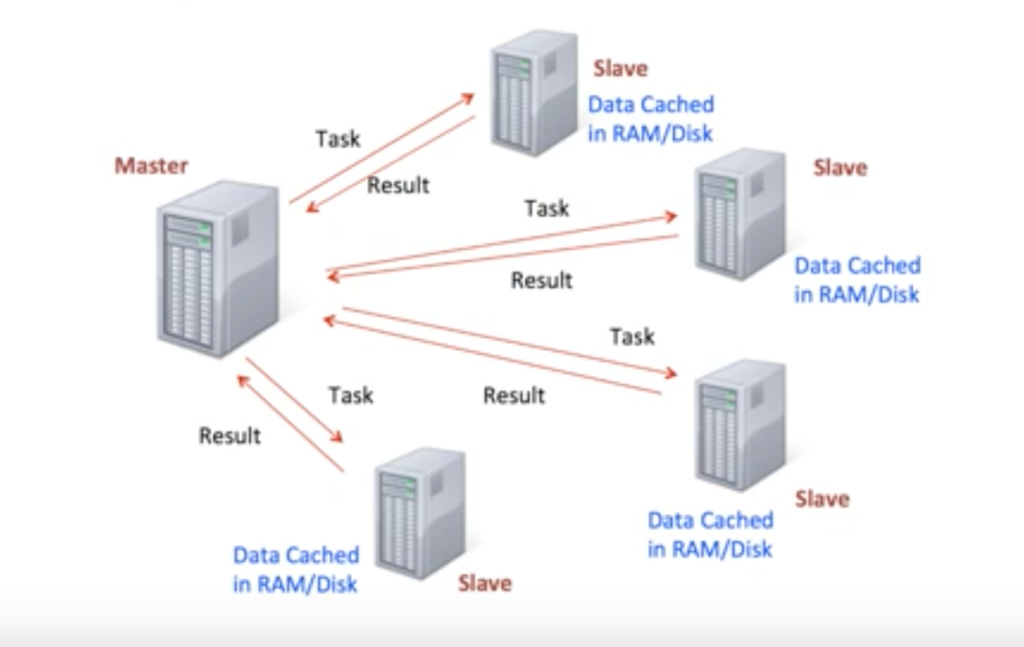
There are two types of Spark operations:
- Transformations -> are basically a recipe to follow
- Actions -> perform what the recipe says to do and returns something back
A lot of times you will write a method call, but won’t see anything as a result until you call the action. This makes sense because with a large dataset, you don’t want to calculate all the transformations until you are sure you want to perform them.




